Pb组包解包实现
Protobuf是Google开源的一套跨平台、跨语言的序列化协议。基于Protocbuf的数据组包方式有效减了网络数据传输的大小,减少流量消耗。
pb协议都是通过*.proto的文件进行描述的,该描述文件是非常通用,不限制针对哪种语言,通过Google提供的compiler可以选择编译的目标编程语言,如java,C++,Python等。这里以C++为例。通过protoc *.proto --cpp_out=dir命令就可以根据proto描述文件生成对应的C++文件*.pb.h和*.pb.cc,然后引用相应的头文件就可以进行组包、解包了。
上面的做法是最基本最常用的,而且我们在使用pb协议的时候也都是这么做的。因为PbCodec不再需要生成C++的头文件了。通过描述文件生成的pb头文件给我们提供的主要方法就是一堆getter、setter、serialize、parse方法,这些方法确实方便了我们组包、解包。
Pb使用((T)([L]V))类似的格式,即Tag-Length-Value。每一个字段值都使用TLV的格式,最后将所有字段的TLV序列拼接为一个二进制字节流进行传输,收到字节流按TLV一个一个字段的解析出来。这里的Tag也可以叫做key,pb使用的格式抽象一下也可以看成是一个个的Key-Value对。
这里的Key也叫Tag是由什么组成的?我们知道在proto描述文件里message下的每个字段值都有一个field数字,表示它在message里是第几个值,我们称它为field_num;声明一个字段的时候还要指定该字段用来放什么类型的值,是可变长度还是固定长度等,这里的字段类型称为wire_type。好了,有了field_num和wire_type我们就可以得到我们的key了,key = field_num << 3 | wire_type。
Protobuf里对wireType声明下面几种类型:
enum WireType {
WIRETYPE_VARINT = 0,
WIRETYPE_FIXED64 = 1,
WIRETYPE_LENGTH_DELIMITED = 2,
WIRETYPE_START_GROUP = 3,
WIRETYPE_END_GROUP = 4,
WIRETYPE_FIXED32 = 5,
};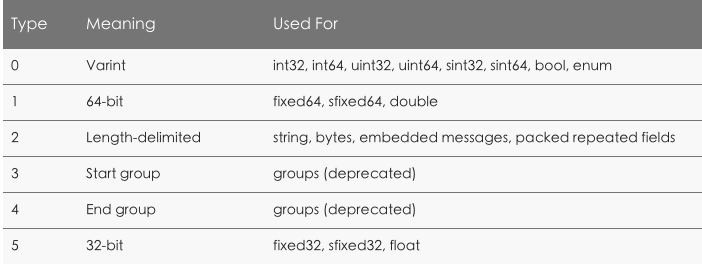
Varint是一种比较特殊的编码方式,后面有详细介绍。FixedXX就是固定长度的。Length_Delimited是针对那些变长数据的如bytes,String,subMessage等。
Value的组成就是由数据长度和数据组成,但是长度可能没有,像对于数字类型的不需要长度,只有那些长度不确定的类型(bytes,string等)需要数据的真实长度才能正确解析。Protobuf的数组格式就是这样的。下面要简单分析下Protobuf的工作原理。
这里我们从具体的pb协议出发,逆向学习pb的原理,下面的图是来电协议oidb_65f和oidb_931里的几个message与Protobuf的类继承关系。
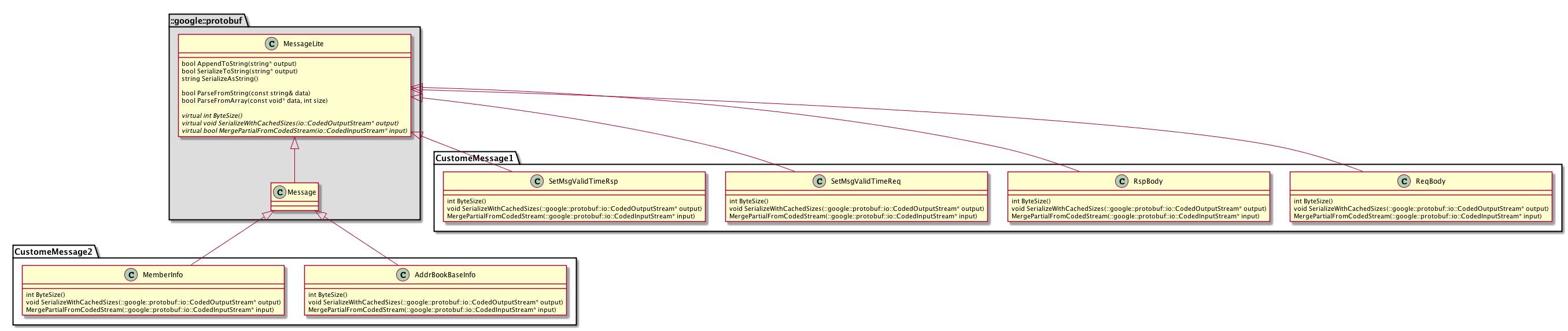
每一条协议都在自己的命名空间中,pb的描述文件中定义的每一个message都会生成一个对应的类,从上面的类关系图中可以看到生成的类中65f协议中类的父类是MessageLite,而931协议中的类的父类是Message,Message又继承自MessageLite,Message类扩充了什么功能呢?我们后面再说。这里最重要是搞明白协议描述文件里的每个message最后生成的类中都有序列化,反序列码的方法了。
看看下面协议中的序列化方法是如何实现的:
void ReqBody::SerializeWithCachedSizes(::google::protobuf::io::CodedOutputStream* output) const {
//optional cmd0x65f.SetMsgValidTimeReq msg_set_req = 1;
if (has_msg_set_req()) {
::google::protobuf::internal::WireFormatLite::WriteMessage(1, this->msg_set_req(),output);
}
}
// optional cmd0x65f.SetMsgValidTimeReq msg_set_req = 1;
inline bool ReqBody::has_msg_set_req() const {
return (_has_bits_[0] & 0x00000001u) != 0;
}从上面代码中可以看出,当要将message进行序列化时,会向CodedOutputStream流中填写,大家自己看一个更复杂点的pb协议的message时,当进行序列化时,会逐一对message下的每个field进行判断,也就是类似上面中的has_msg_set_req(),如果有设置值就会进行写操作,每当对一个字段进行设置值时都会设置对应的标志位。::google::protobuf::uint32 _has_bits_[(1 + 31) / 32];对于每一个message都会根据field的个数来生成一个这样的数组,用来标志每个字段的是否有值,同样在解包的时候也会有对应设置。假设message下有40个字段,则会有::google::protobuf::uint32 _has_bits_[(40 + 31) / 32];这样的数组。若对应字段有值,就调用WriteXXXX方法写入流中。这里会根据字段声明时的值类型调用不同的Write方法,因为在此处的field是另一个message,因此会调用WriteMessage方法,如果是uint32类型,刚会调用WriteUInt32方法,这些Write方法都是相似的。下面看WriteMessage实现:
void WireFormatLite::WriteMessage(int field_number,
const MessageLite& value,
io::CodedOutputStream* output) {
WriteTag(field_number, WIRETYPE_LENGTH_DELIMITED, output);
const int size = value.GetCachedSize();
output->WriteVarint32(size);
value.SerializeWithCachedSizes(output);
}
inline void WireFormatLite::WriteTag(int field_number, WireType type,
io::CodedOutputStream* output) {
output->WriteTag(MakeTag(field_number, type));
}
inline uint32 WireFormatLite::MakeTag(int field_number, WireType type) {
return GOOGLE_PROTOBUF_WIRE_FORMAT_MAKE_TAG(field_number, type);
}
#define GOOGLE_PROTOBUF_WIRE_FORMAT_MAKE_TAG(FIELD_NUMBER, TYPE) \
static_cast<uint32>( \
((FIELD_NUMBER) << ::google::protobuf::internal::WireFormatLite::kTagTypeBits) \
| (TYPE))WriteMessage的第一个参数是field_number也就是message中字段的序号,从前面也看到在调用的时候传的第一个参数的值是1,也就是field的序号。方法中首先调用WriteTag方法,从代码中可以看出Tag就是按照之前说的方法field_num << 3 | wire_type生成的。写完tag,因为WireType是变长的,因此要告诉数据长度,接着写数据长度output->WriteVarint32(size);,后面再写入数据。 这样message的序列化的核心工作就完成了,当然我们不会直接调用这里的ReqBody::SerializeWithCachedSizes方法来生成组包的数据buffer。我们调用的序列化方法是MessageLite::SerializeAsString()或是MessageLite::SerializeToString(string* output),然后这两个方法再经过层层调用到达我们的message的SerializeWithCachedSizes方法,最终得到序列化后的结果。
现在pb如何进行序列化我们已经知道了,现在看pb怎么进行反序列化。先上代码了解下:
bool RspBody::MergePartialFromCodedStream(::google::protobuf::io::CodedInputStream* input) {
#define DO_(EXPRESSION) if (!(EXPRESSION)) return false
::google::protobuf::uint32 tag;
while ((tag = input->ReadTag()) != 0) {
switch (::google::protobuf::internal::WireFormatLite::GetTagFieldNumber(tag)) {
// optional cmd0x65f.SetMsgValidTimeRsp msg_set_rsp = 1;
case 1: {
if (::google::protobuf::internal::WireFormatLite::GetTagWireType(tag) ==
::google::protobuf::internal::WireFormatLite::WIRETYPE_LENGTH_DELIMITED) {
DO_(::google::protobuf::internal::WireFormatLite::ReadMessageNoVirtual(input, mutable_msg_set_rsp()));
} else {
goto handle_uninterpreted;
}
if (input->ExpectAtEnd()) return true;
break;
}
default: {
handle_uninterpreted:
if (::google::protobuf::internal::WireFormatLite::GetTagWireType(tag) ==
::google::protobuf::internal::WireFormatLite::WIRETYPE_END_GROUP) {
return true;
}
DO_(::google::protobuf::internal::WireFormatLite::SkipField(input, tag));
break;
}
}
}
return true;
#undef DO_
}上面的反序列化代码是针对特定message的,因此每个message都会有自己的反序列化实现。上面反序列化方法的参数是一个输入流,不用想也知道是一串二进制流,通过循环不停的读取tag,然后根据tag得到field_num,然后就是读值了。首先有没有这样的疑问,pb怎么知道读出来的WireType是对的呢,跟哪种类型进行比较呢?因为在根据描述文件生成这些方法的时候都知道每个字段的数据类型,也就知道在序列化时用的是哪个WireType了,同样也知道该调用哪个方法来读取值,并写入哪个字段。在搞明白了序列化操作后,反序列化就没有那么神秘了。
反序列化首先要读取Tag,但是这里我们看到的是一串二进制数据,在读取Tag时如何判断结束条件呢?有了这个疑问,我们就需要了解Protobuf的Varint编码,这是一种比较特殊的编码方式。
对于int32类型的数字,一般需要4个byte 来表示。但是采用 Varint,对于很小的int32 类型的数字,则可以用 1个byte来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。下面就详细介绍一下 Varint。
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:1010 1100 0000 0010
下图演示了 Google Protocol Buffer 如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用 little-endian 的方式。
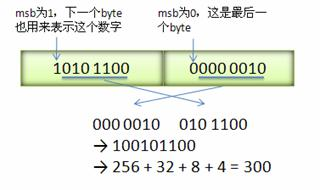
对Varint编码了解后,前面ReadTag时就是这样来判断结束条件的。但是大家有没有疑问,就是前面说的Tag(也叫Key)是按field_num << 3 | Wire_type生成的,这里field_num左移3位会不会导致数据丢失呢?这里就假设field_num是uint32类型的,左移3位依然能表示2^28个,相信在一个message里不会达到这么多字段吧,因此完全够用。而且对Tag进行Varint编码的是field_num << 3 | Wire_type这个结果。
题外篇
对于在proto描述文件中添加option optimize_for = LITE_RUNTIM到底有什么用呢?
当添加后在编译proto文件时编译器会使用libprotobuf-lite库而不是libprotobuf库,使用libprotobuf-lite我们的message生成的类会继承自MessageLite,如果使用libprotobuf,生成的类则继承自Message。然后Message又继承自MessageLite,并且添加了descriptor和reflection特性,这会导致生成的头文件中有支持这两个特性的相关代码,然后我们日常使用pb时根本用不到这两个特性,因此完全没有必要保留着他们。这也是为什么添加这个优化选项的原因了。对于这两个特性有什么功能大家可以自己去探索下。
这个原来是内部分享时写的,去除了部分内容,希望对于想要学习Pb的同学有所帮助。Pb的确是很优秀的序列化方法,值得深入研究学习。基于Pb也可以创造其他的一些工具,数据存储等方案。
本文是删减版本,如果有什么不清楚的地方,请留言进一步沟通。